28 Linear Regression
Linear regression is a very elegant, simple, powerful and commonly used technique for data analysis. We use it extensively in exploratory data analysis (we used in project 2, for example) and in statistical analyses since it fits into the statistical framework we saw in the last unit, and thus lets us do things like construct confidence intervals and hypothesis testing for relationships between variables. It also provides predictions for continuous outcomes of interest.
Note: Much of this development is based on “Introduction to Statistical Learning” by James, Witten, Hastie and Tibshirani. http://www-bcf.usc.edu/~gareth/ISL/
28.1 Simple Regression
Let’s start with the simplest linear model. The goal here is to analyze the relationship between a continuous numerical variable \(Y\) and another (numerical or categorical) variable \(X\). We assume that in our population of interest the relationship between the two is given by a linear function:
\[ Y = \beta_0 + \beta_1 X \]
Here is (simulated) data from an advertising campaign measuring sales and the amount spent in advertising. We think that sales are related to the amount of money spent on TV advertising:
\[ \mathtt{sales} \approx \beta_0 + \beta_1 \times \mathtt{TV} \]
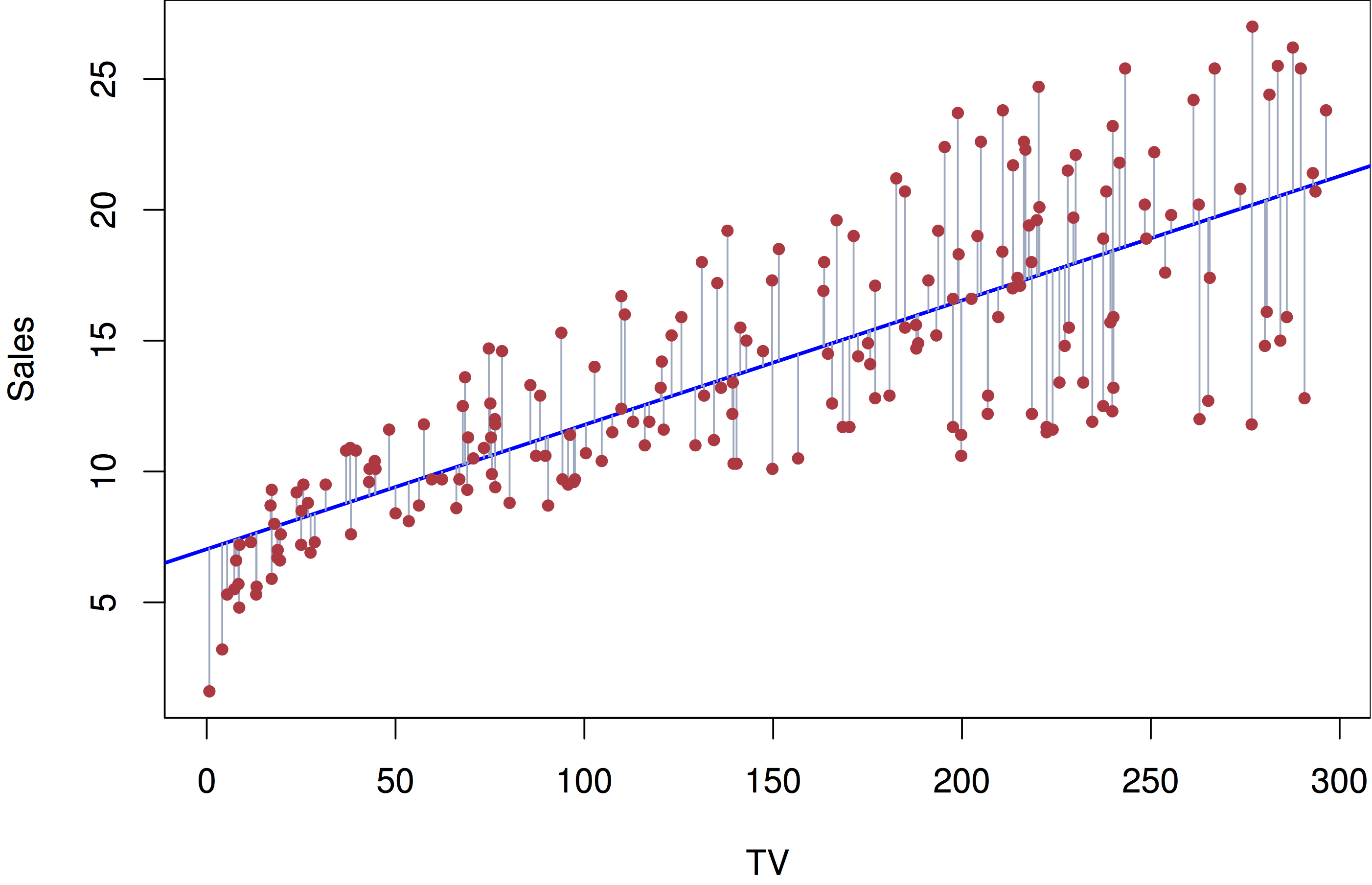
Given this data, we would say that we regress sales on TV when we perform this regression analysis. As before, given data we would like to estimate what this relationship is in the population (what is the population in this case?). What do we need to estimate in this case? Values for \(\beta_0\) and \(\beta_1\). What is the criteria that we use to estimate them?
Just like the previous unit we need to setup an inverse problem. What we are stating mathematically in the linear regression problem is that the conditional expectation (or conditional mean, conditional average) of \(Y\) given \(X=x\) is defined by this linear relationship:
\[ \mathbb{E}[Y|X=x] = \beta_0 + \beta_1 x \]
Given a dataset, the inverse problem is then to find the values of \(\beta_0\) and \(\beta_1\) that minimize deviation between data and expectation, and again use squared devation to do this.
The linear regression problem
Given data \((x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\), find values \(\beta_0\) and \(\beta_1\) that minimize objective or loss function RSS (residual sum of squares):
\[ \arg \min_{\beta_0,\beta_1} RSS = \frac{1}{2} \sum_i (y_i - (\beta_0 + \beta_1 x_i))^2 \]
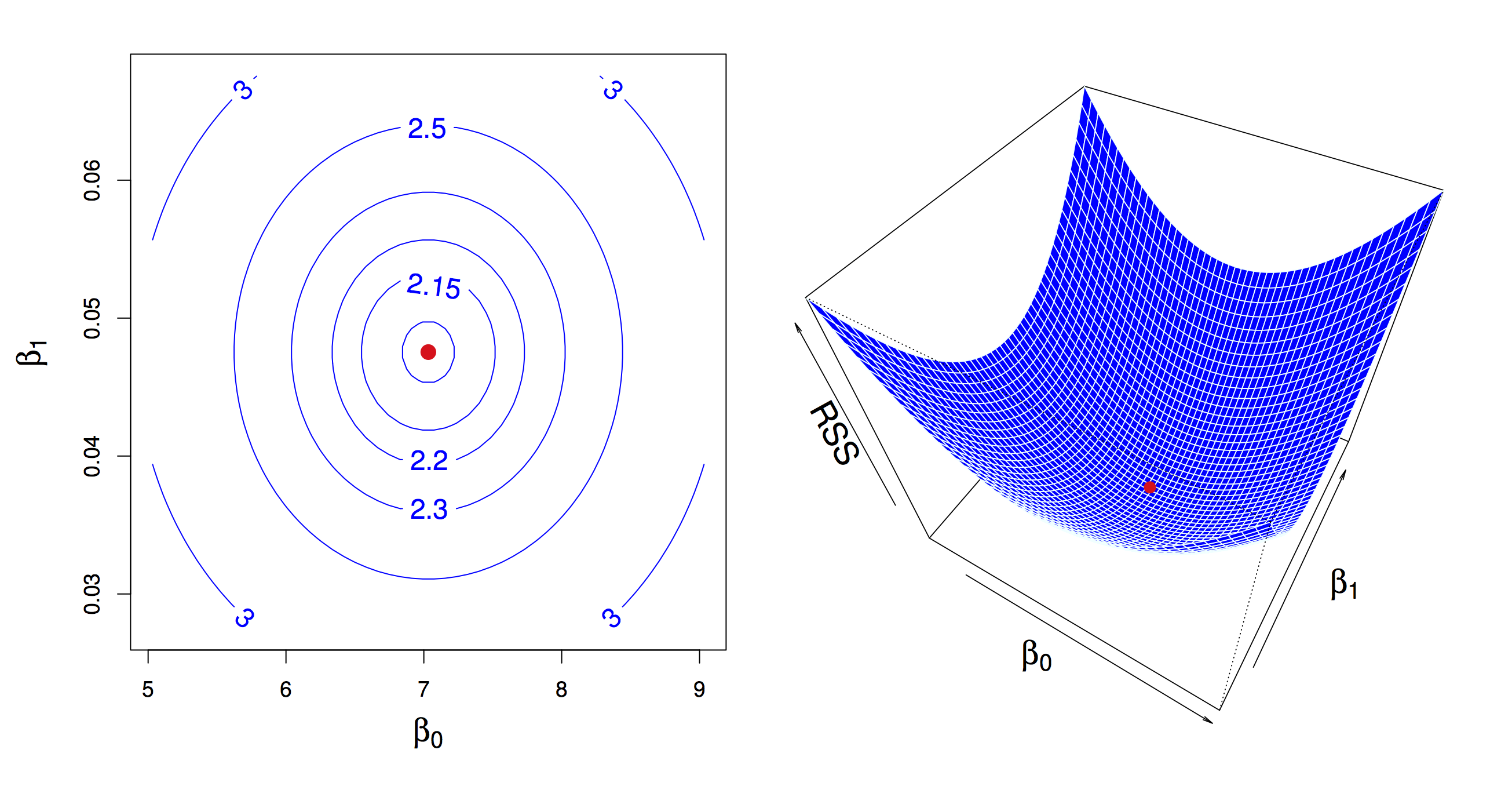
Similar to what we did with the derivation of the mean as a measure of central tendency we can derive the values of minimizers\(\hat{\beta}_0\) and \(\hat{\beta}_1\). We use the same principle, compute derivatives (partial this time) of the objective function RSS, set to zero and solve to obtain:
\[ \begin{aligned} \hat{\beta}_1 & = \frac{\sum_{i=1}^n (y_i - \overline{y})(x_i - \overline{x})}{\sum_{i=1}^n (x_i - \overline{x})^2} \\ {} & = \frac{\mathrm{cov}(y,x)}{\mathrm{var}(x)} \\ \hat{\beta}_0 & = \overline{y} - \hat{\beta}_1 \overline{x} \end{aligned} \]
Let’s take a look at some data. Here is data measuring characteristics of cars, including horsepower, weight, displacement, miles per gallon. Let’s see how well a linear model captures the relationship between miles per gallon and weight
library(ISLR)
library(tidyverse)
data(Auto)
Auto %>%
ggplot(aes(x=weight, y=mpg)) +
geom_point() +
geom_smooth(method=lm) +
theme_minimal()
In R, linear models are built using the lm function
##
## Call:
## lm(formula = mpg ~ weight, data = Auto)
##
## Coefficients:
## (Intercept) weight
## 46.216525 -0.007647This states that for this dataset \(\hat{\beta}_0 = 46.2165245\) and \(\hat{\beta}_1 = -0.0076473\). What’s the interpretation? According to this model, a weightless car weight=0 would run \(\approx 46.22\) miles per gallon on average, and, on average, a car would run \(\approx 0.01\) miles per gallon fewer for every extra pound of weight. Note, that the units of the outcome \(Y\) and the predictor \(X\) matter for the interpretation of these values.
28.2 Inference
As we saw in the last unit, now that we have an estimate, we want to know its precision. We will see that similar arguments based on the CLT hold again. The main point is to understand that like the sample mean, the regression line we learn from a specific dataset is an estimate. A different sample from the same population would give us a different estimate (regression line). But, the CLT tells us that, on average, we are close to population regression line (I.e., close to \(\beta_0\) and \(\beta_1\)), that the spread around \(\beta_0\) and \(\beta_1\) is well approximated by a normal distribution and that the spread goes to zero as the sample size increases.
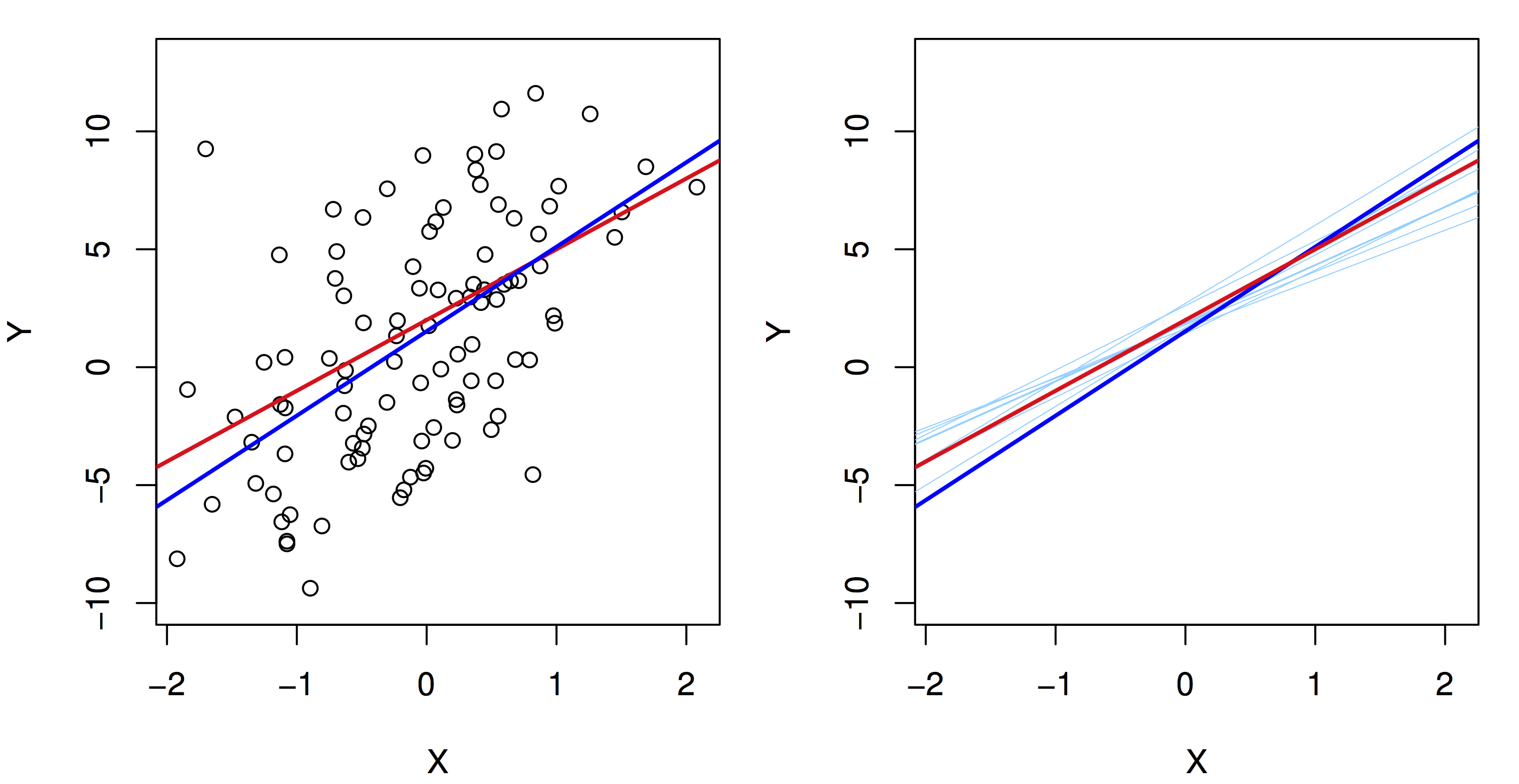
28.2.1 Confidence Interval
Using the same framework as before, we can construct a confidence interval to say how precise we think our estimates of the population regression line is. In particular, we want to see how precise our estimate of \(\beta_1\) is, since that captures the relationship between the two variables. We again, use a similar framework. First, we calculate a standard error estimate for \(\beta_1\):
\[ \mathrm{se}(\hat{beta}_1)^2 = \frac{\sum_i (y_i - \hat{y}_i)^2}{\sum_i (x_i - \overline{x})^2} \]
and construct a 95% confidence interval
\[ \beta_1 = \hat{\beta}_1 \pm 1.95 \times \mathrm{se}(\hat{beta}_1) \]
Note, \(\hat{y}_i = \hat{\beta}_0 + \hat{\beta}_1 x_i\). Going back to our example:
## # A tibble: 2 x 3
## term estimate std.error
## <chr> <dbl> <dbl>
## 1 (Intercept) 46.2 0.799
## 2 weight -0.00765 0.000258This tidy function is defined by the broom package, which is very handy to manipulate the result of learning models in a consistent manner. The select call removes some extra information that we will discuss shortly.
confidence_interval_offset <- 1.95 * auto_fit_stats$std.error[2]
confidence_interval <- round(c(auto_fit_stats$estimate[2] - confidence_interval_offset,
auto_fit_stats$estimate[2],
auto_fit_stats$estimate[2] + confidence_interval_offset), 4)Given the confidence interval, we would say, “on average, a car runs \(_{-0.0082} -0.0076_{-0.0071}\) miles per gallon fewer per pound of weight.
28.2.2 The \(t\)-statistic and the \(t\)-distribution
As in the previous unit, we can also test a null hypothesis about this relationship: “there is no relationship between weight and miles per gallon”, which translates to \(\beta_1=0\). Again, using the same argument based on the CLT, if this hypothesis is true then the distribution of \(\hat{\beta}_1\) is well approximated by \(N(0,\mathrm{se}(\hat{\beta}_1))\), and if we observe the learned \(\hat{\beta}_1\) is too far from 0 according to this distribution then we reject the hypothesis.
Now, there is a technicality here that we did not discuss in the previous unit that is worth paying attention to. We saw before that the CLT states that the normal approximation is good as sample size increases, but what about moderate sample sizes (say, less than 100)? The \(t\) distribution provides a better approximation of the sampling distribution of these estimates for moderate sample sizes, and it tends to the normal distribution as sample size increases.
The \(t\) distribution is commonly used in this testing situation to obtain the probability of rejecting the null hypothesis. It is based on the \(t\)-statistic
\[ \frac{\hat{\beta}_1}{\mathrm{se}(\hat{\beta}_1)} \]
You can think of this as a signal-to-noise ratio, or a standardizing transformation on the estimated parameter. Under the null hypothesis, the \(t\)-statistic is well approximated by a \(t\)-distribution with \(n-2\) degrees of freedom (we will get back to degrees of freedom shortly). Like other distributions, you can compute with the \(t\)-distribution using the p,d,q,r-family of functions, e.g., pt is the cumulative probability distribution function.
In our example, we get a \(t\) statistic and P-value as follows:
## # A tibble: 2 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Interc… 46.2 0.799 57.9 1.62e-193
## 2 weight -0.00765 0.000258 -29.6 6.02e-102We would say: “We found a statistically significant relationship between weight and miles per gallon. On average, a car runs \(_{-0.0082} -0.0076_{-0.0071}\) miles per gallon fewer per pound of weight (\(t\)=-29.65, \(p\)-value<6.015296110^{-102}$).”
28.2.3 Global Fit
Now, notice that we can make predictions based on our conditional expectation, and that prediction should be better than a prediction with a simple average. We can use this comparison as a measure of how good of a job we are doing using our model to fit this data: how much of the variance of \(Y\) can we explain with our model. To do this we can calculate total sum of squares:
\[ TSS = \sum_i (y_i - \overline{y})^2 \]
(this is the squared error of a prediction using the sample mean of \(Y\))
and the residual sum of squares:
\[ RSS = \sum_i (y_i - \hat{y}_i)^2 \]
(which is the squared error of a prediction using the linear model we learned)
The commonly used \(R^2\) measure comparse these two quantities:
\[ R^2 = \frac{\mathrm{TSS}-\mathrm{RSS}}{\mathrm{TSS}} = 1 - \frac{\mathrm{RSS}}{\mathrm{TSS}} \]
These types of global statistics for the linear model can be obtained using the glance function in the broom package. In our example
## # A tibble: 1 x 5
## r.squared sigma statistic df p.value
## <dbl> <dbl> <dbl> <int> <dbl>
## 1 0.693 4.33 879. 2 6.02e-102We will explain the the columns statistic, df and p.value when we discuss regression using more than a single predictor \(X\).
28.3 Some important technicalities
We mentioned above that predictor \(X\) could be numeric or categorical. However, this is not precisely true. We can use a transformation to represent categorical variables. Here is a simple example:
Suppose we have a categorical variable sex with values female and male, and we want to show the relationship between, say credit card balance and sex. We can create a dummy variable \(x\) as follows:
\[ x_i = \left\{ \begin{aligned} 1 & \textrm{ if female} \\ 0 & \textrm{o.w.} \end{aligned} \right. \]
and fit a model \(y = \beta_0 + \beta_1 x\). What is the conditional expectation given by this model? If the person is male, then \(y=\beta_0\), if the person is female, then \(y=\beta_0 + \beta_1\). So, what is the interpretation of \(\beta_1\)? The average difference in credit card balance between females and males.
We could do a different encoding:
\[ x_i = \left\{ \begin{aligned} +1 & \textrm{ if female} \\ -1 & \textrm{o.w.} \end{aligned} \right. \]
Then what is the interpretation of \(\beta_1\) in this case?
Note, that when we call the lm(y~x) function and x is a factor with two levels, the first transformation is used by default. What if there are more than 2 levels? We need multiple regression, which we will see shortly.
28.4 Issues with linear regression
There are some assumptions underlying the inferences and predictions we make using linear regression that we should verify are met when we use this framework. Let’s start with four important ones that apply to simple regression
28.4.1 Non-linearity of outcome-predictor relationship
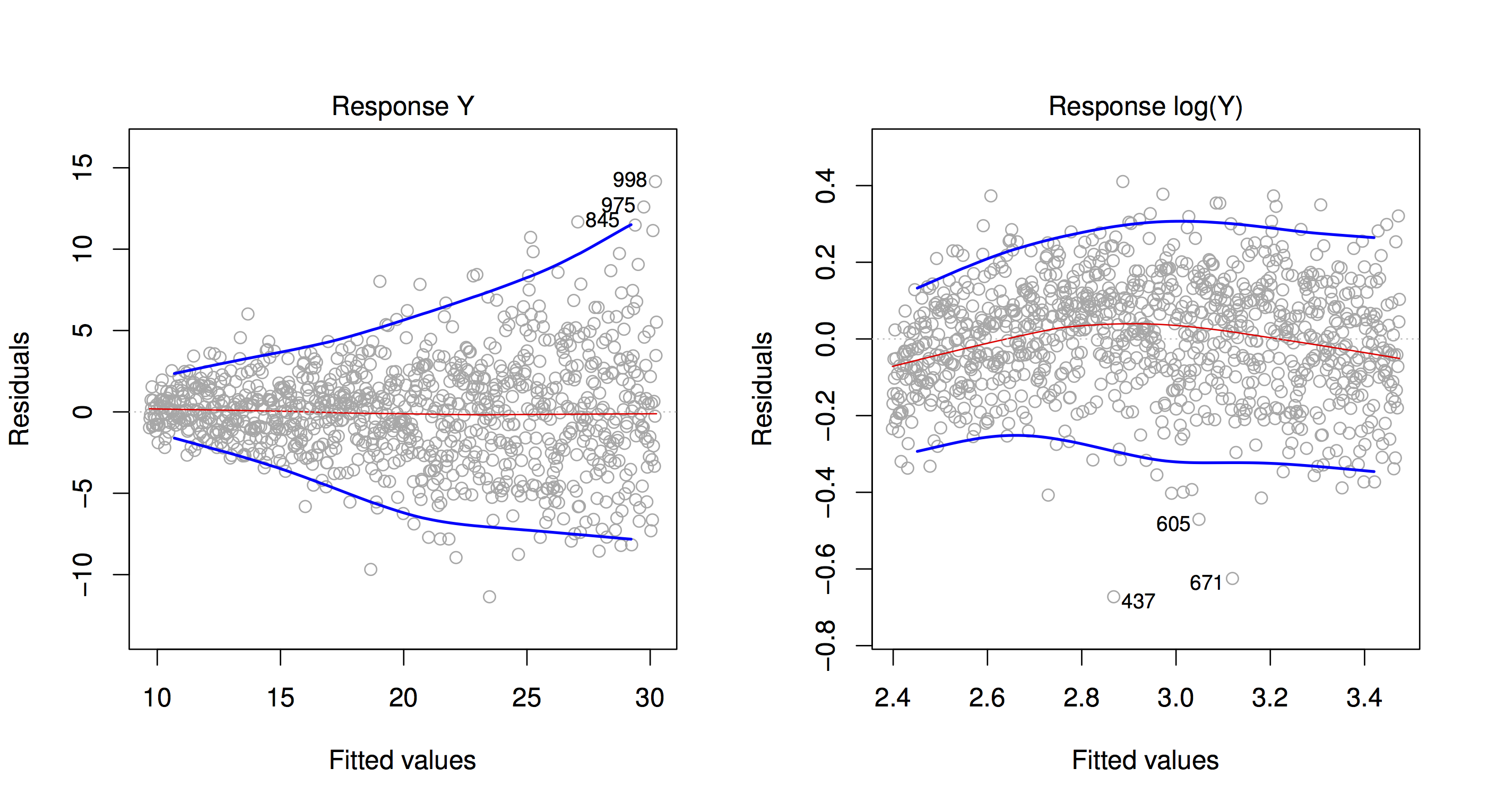
What if the underlying relationship is not linear? We will see later that we can capture non-linear relationships between variables, but for now, let’s concentrate on detecting if a linear relationship is a good approximation. We can use exploratory visual analysis to do this for now by plotting residuals \((y_i - \hat{y}_i)^2\) as a function of the fitted values \(\hat{y}_i\).
The broom package uses the augment function to help with this task. It augments the input data used to learn the linear model with information of the fitted model for each observation
## # A tibble: 6 x 10
## .rownames mpg weight .fitted .se.fit .resid
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 18 3504 19.4 0.258 -1.42
## 2 2 15 3693 18.0 0.286 -2.97
## 3 3 18 3436 19.9 0.249 -1.94
## 4 4 16 3433 20.0 0.248 -3.96
## 5 5 17 3449 19.8 0.250 -2.84
## 6 6 15 4341 13.0 0.414 1.98
## # … with 4 more variables: .hat <dbl>,
## # .sigma <dbl>, .cooksd <dbl>,
## # .std.resid <dbl>With that we can make the plot we need to check for possible non-linearity
augmented_auto %>%
ggplot(aes(x=.fitted,y=.resid)) +
geom_point() +
geom_smooth() +
labs(x="fitted", y="residual")## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
28.4.2 Correlated Error
For our inferences to be valid, we need residuals to be independent and identically distributed. We can spot non independence if we observe a trend in residuals as a function of the predictor \(X\). Here is a simulation to demonstrate this:
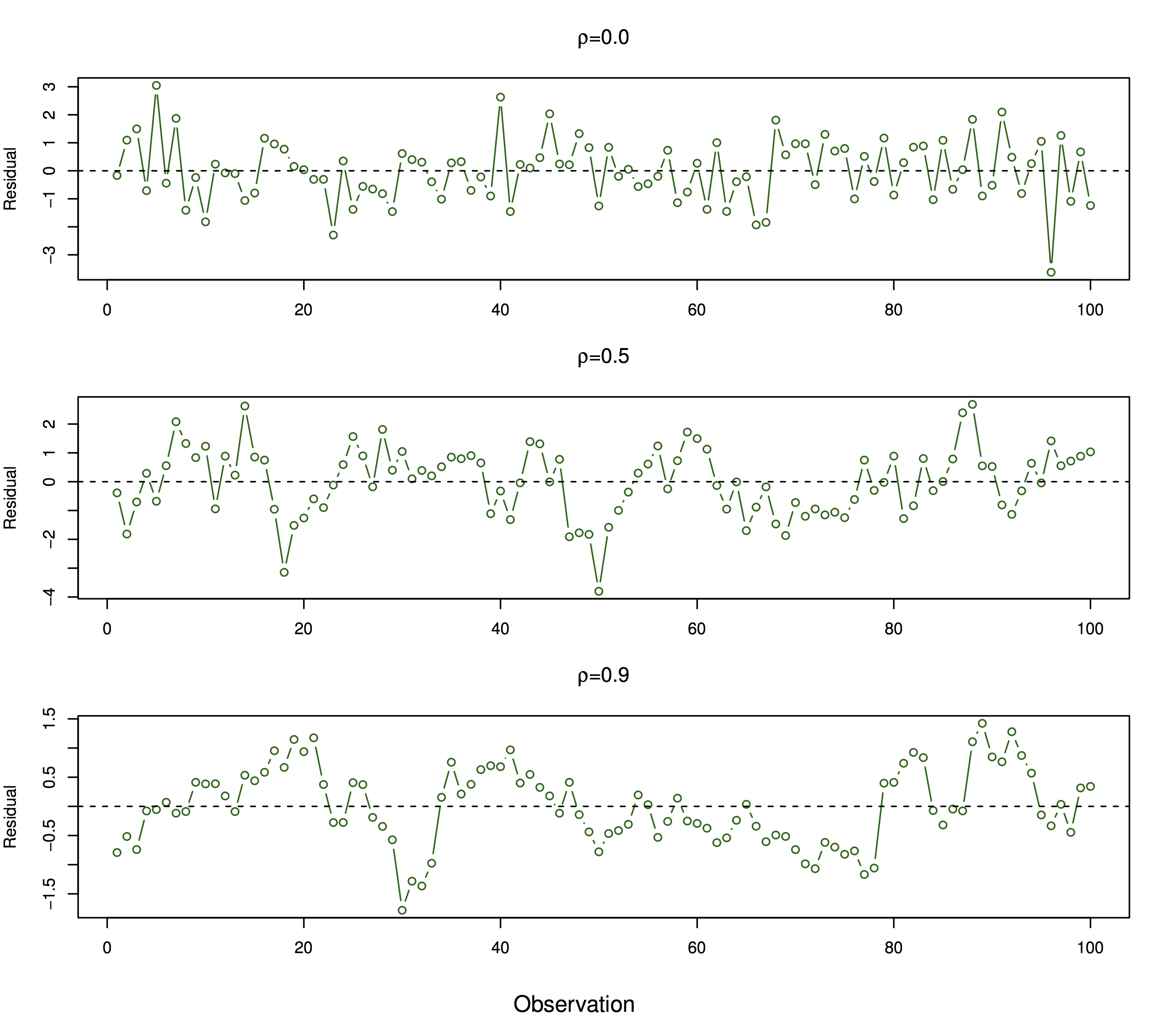
In this case, our standard error estimates would be underestimated and our confidence intervals and hypothesis testing results would be biased.
28.4.3 Non-constant variance
Another violation of the iid assumption would be observed if the spread of residuals is not independent of the fitted values. Here is an illustration, and a possible fix using a log transformation on the outcome \(Y\).
28.5 Multiple linear regression
Now that we’ve seen regression using a single predictor we’ll move on to regression using multiple predictors. In this case, we use models of conditional expectation represented as linear functions of multiple variables:
\[ \mathbb{E}[Y|X_1=x_1,X_2=x_2,\ldots,X_p=x_p] = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots \beta_3 x_3 \]
In the case of our advertising example, this would be a model:
\[ \mathtt{sales} = \beta_0 + \beta_1 \times \mathtt{TV} + \beta_2 \times \mathtt{newspaper} + \beta_3 \times \mathtt{facebook} \]
These models let us make statements of the type: “holding everything else constant, sales increased on average by 1000 per dollar spent on Facebook advertising” (this would be given by parameter \(\beta_3\) in the example model).
28.5.1 Estimation in multivariate regression
Generalizing simple regression, we estimate \(\beta\)’s by minimizing an objective function that represents the difference between observed data and our expectation based on the linear model:
\[ \begin{aligned} RSS & = \frac{1}{2} \sum_{i=1}^n (y_i - \hat{y}_i)^2 \\ {} & = \frac{1}{2} \sum_{i=1}^n (y_i - (\beta_0 + \beta_1 x_1 + \cdots + \beta_p x_p))^2 \end{aligned} \]
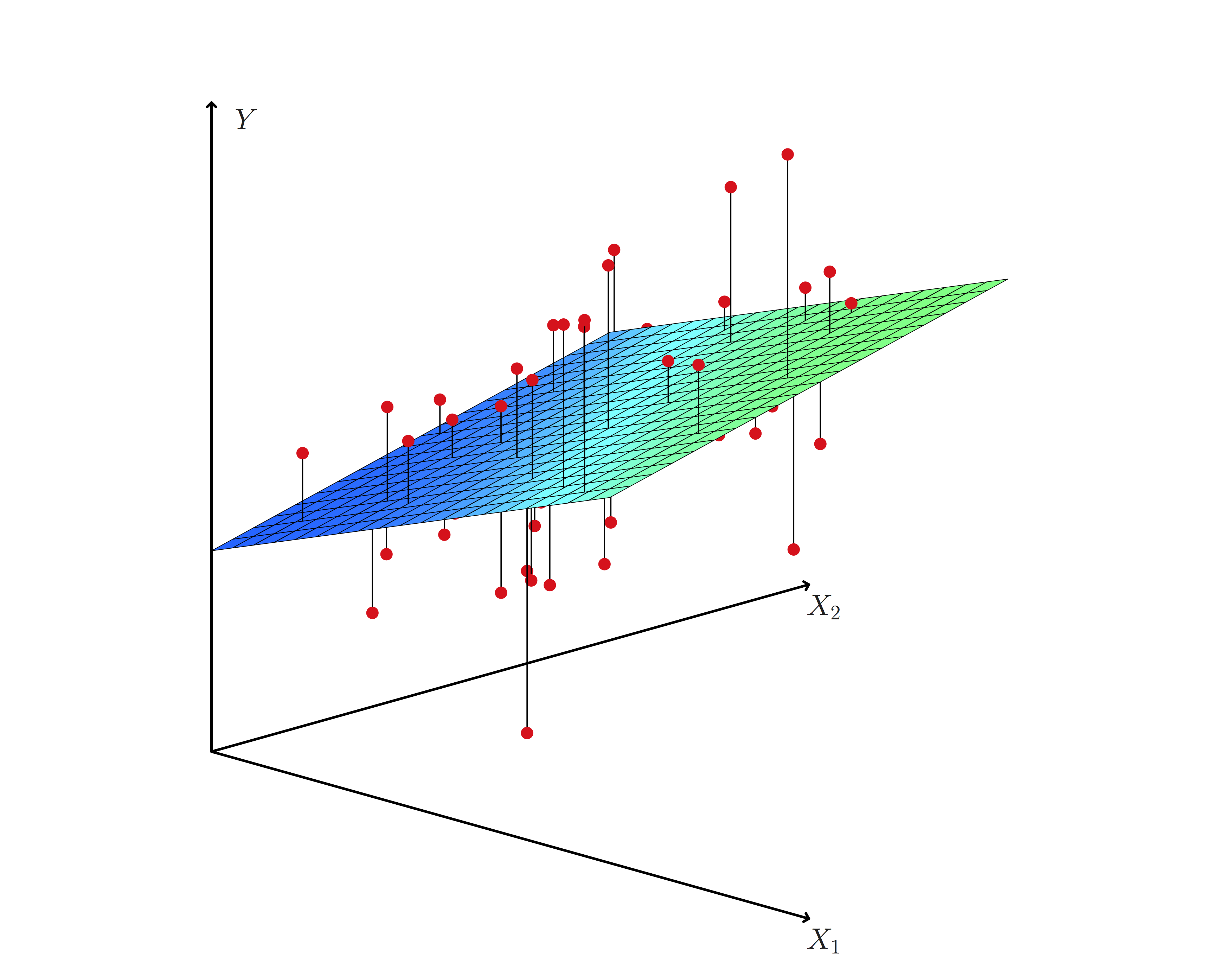
The minimizer is found using numerical algorithms to solve this type of least squares problems. These are covered in Linear Algebra courses, and include the QR decomposition, Gauss-Seidel method, and many others. Later in the course we will look at stochastic gradient descent, a simple algorithm that scales to very large datasets.
28.5.2 Example (cont’d)
Continuing with our Auto example, we can build a model for miles per gallon using multiple predictors:
##
## Call:
## lm(formula = mpg ~ 1 + weight + cylinders + horsepower + displacement +
## year, data = Auto)
##
## Coefficients:
## (Intercept) weight cylinders
## -12.779493 -0.006524 -0.343690
## horsepower displacement year
## -0.007715 0.006996 0.749924From this model we can make the statement: “Holding everything else constant, cars run 0.76 miles per gallon more each year on average”.
28.5.3 Statistical statements (cont’d)
Like simple linear regression, we can construct confidence intervals, and test a null hypothesis of no relationship (\(\beta_j=0\)) for the parameter corresponding to each predictor. This is again nicely managed by the broom package:
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | -12.7794934 | 4.2739387 | -2.9900975 | 0.0029676 |
| weight | -0.0065245 | 0.0005866 | -11.1215621 | 0.0000000 |
| cylinders | -0.3436900 | 0.3315619 | -1.0365786 | 0.3005812 |
| horsepower | -0.0077149 | 0.0107036 | -0.7207702 | 0.4714872 |
| displacement | 0.0069964 | 0.0073095 | 0.9571736 | 0.3390787 |
| year | 0.7499243 | 0.0524361 | 14.3016700 | 0.0000000 |
In this case we would reject the null hypothesis of no relationship only for predictors weight and year. We would write the statement for year as follows:
“Holding everything else constant, cars run \({}_{0.65} 0.75_{0.85}\) miles per gallon more each year on average (P-value=P-value<1e-16)”.
28.5.4 The F-test
We can make additional statements for multivariate regression: “is there a relationship between any of the predictors and the response?”. Mathematically, we write this as \(\beta_1 = \beta_2 = \cdots = \beta_p = 0\).
Under the null, our model for \(y\) would be estimated by the sample mean \(\overline{y}\), and the error for that estimate is by total sum of squared error \(TSS\). As before, we can compare this to the residual sum of squared error \(RSS\) using the \(F\) statistic:
\[ \frac{(\mathrm{TSS}-\mathrm{RSS})/p}{\mathrm{RSS}/(n-p-1)} \]
If this statistic is greater (enough) than 1, then we reject hypothesis that there is no relationship between response and predictors.
Back to our example, we use the glance function to compute this type of summary:
| r.squared | sigma | statistic | df | p.value |
|---|---|---|---|---|
| 0.8089093 | 3.433902 | 326.7965 | 6 | 0 |
In comparison with the linear model only using weight, this multivariate model explains more of the variance of mpg, but using more predictors. This is where the notion of degrees of freedom comes in: we now have a model with expanded representational ability.
However, the bigger the model, we are conditioning more and more, and intuitively, given a fixed dataset, have fewer data points to estimate conditional expectation for each value of the predictors. That means, that are estimated conditional expectation is less precise.
To capture this phenomenon, we want statistics that tradeoff how well the model fits the data, and the “complexity” of the model. Now, we can look at the full output of the glance function:
| r.squared | adj.r.squared | sigma | statistic | p.value | df | logLik | AIC | BIC | deviance | df.residual |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.8089093 | 0.806434 | 3.433902 | 326.7965 | 0 | 6 | -1036.81 | 2087.62 | 2115.419 | 4551.589 | 386 |
Columns AIC and BIC display statistics that penalize model fit with model size. The smaller this value, the better. Let’s now compare a model only using weight, a model only using weight and year and the full multiple regression model we saw before.
| r.squared | adj.r.squared | sigma | statistic | p.value | df | logLik | AIC | BIC | deviance | df.residual |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.6926304 | 0.6918423 | 4.332712 | 878.8309 | 0 | 2 | -1129.969 | 2265.939 | 2277.852 | 7321.234 | 390 |
| r.squared | adj.r.squared | sigma | statistic | p.value | df | logLik | AIC | BIC | deviance | df.residual |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.8081803 | 0.8071941 | 3.427153 | 819.473 | 0 | 3 | -1037.556 | 2083.113 | 2098.998 | 4568.952 | 389 |
In this case, using more predictors beyond weight and year doesn’t help.
28.5.5 Categorical predictors (cont’d)
We saw transformations for categorical predictors with only two values, and deferred our discussion of categorical predictors with more than two values. In our example we have the origin predictor, corresponding to where the car was manufactured, which has multiple values
## [1] "1" "2" "3"As before, we can only use numerical predictors in linear regression models. The most common way of doing this is to create new dummy predictors to encode the value of the categorical predictor. Let’s take a categorical variable major that can take values CS, MATH, BUS. We can encode these values using variables \(x_1\) and \(x_2\)
\[ x_1 = \left\{ \begin{aligned} 1 & \textrm{ if MATH} \\ 0 & \textrm{ o.w.} \end{aligned} \right. \]
\[ x_2 = \left\{ \begin{aligned} 1 & \textrm{ if BUS} \\ 0 & \textrm{ o.w.} \end{aligned} \right. \]
Now let’s build a model to capture the relationship between salary and major:
\[ \mathtt{salary} = \beta_0 + \beta_1 x_1 + \beta_2 x_2 \]
What is the expected salary for a CS major? \(\beta_0\).
For a MATH major? \(\beta_0 + \beta_1\).
For a BUS major? \(\beta_0 + \beta_2\).
So, \(\beta_1\) is the average difference in salary between MATH and CS majors. How can we calculate the average difference in salary between MATH and BUS majors? \(\beta_1 - \beta_2\).
The lm function in R does this transformation by default when a variable has class factor.
We can see what the underlying numerical predictors look like by using the model_matrix function and passing it the model formula we build:
extended_df <- model.matrix(~origin, data=Auto) %>%
as.data.frame() %>%
mutate(origin = Auto$origin)
extended_df %>%
filter(origin == "1") %>% head()## (Intercept) origin2 origin3 origin
## 1 1 0 0 1
## 2 1 0 0 1
## 3 1 0 0 1
## 4 1 0 0 1
## 5 1 0 0 1
## 6 1 0 0 1## (Intercept) origin2 origin3 origin
## 1 1 1 0 2
## 2 1 1 0 2
## 3 1 1 0 2
## 4 1 1 0 2
## 5 1 1 0 2
## 6 1 1 0 2## (Intercept) origin2 origin3 origin
## 1 1 0 1 3
## 2 1 0 1 3
## 3 1 0 1 3
## 4 1 0 1 3
## 5 1 0 1 3
## 6 1 0 1 328.6 Interactions in linear models
The linear models so far include additive terms for a single predictor. That let us made statemnts of the type “holding everything else constant…”. But what if we think that a pair of predictors together have a relationship with the outcome. We can add these interaction terms to our linear models as products:
\[ \mathbb{E} Y|X_1=x_1,X_2=x2 = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_{12} x_1 x_2 \]
Consider the advertising example:
\[ \mathtt{sales} = \beta_0 + \beta_1 \times \mathtt{TV} + \beta_2 \times \mathtt{facebook} + \beta_3 \times (\mathtt{TV} \times \mathtt{facebook}) \]
If \(\beta_3\) is positive, then the effect of increasing TV advertising money is increased if facebook advertising is also increased.
When using categorical variables, interactions have an elegant interpretation. Consider our car example, and suppose we build a model with an interaction between weight and origin. Let’s look at what the numerical predictors look like:
extended_df <- model.matrix(~weight+origin+weight:origin, data=Auto) %>%
as.data.frame() %>%
mutate(origin = Auto$origin)
extended_df %>%
filter(origin == "1") %>% head()## (Intercept) weight origin2 origin3
## 1 1 3504 0 0
## 2 1 3693 0 0
## 3 1 3436 0 0
## 4 1 3433 0 0
## 5 1 3449 0 0
## 6 1 4341 0 0
## weight:origin2 weight:origin3 origin
## 1 0 0 1
## 2 0 0 1
## 3 0 0 1
## 4 0 0 1
## 5 0 0 1
## 6 0 0 1## (Intercept) weight origin2 origin3
## 1 1 1835 1 0
## 2 1 2672 1 0
## 3 1 2430 1 0
## 4 1 2375 1 0
## 5 1 2234 1 0
## 6 1 2123 1 0
## weight:origin2 weight:origin3 origin
## 1 1835 0 2
## 2 2672 0 2
## 3 2430 0 2
## 4 2375 0 2
## 5 2234 0 2
## 6 2123 0 2## (Intercept) weight origin2 origin3
## 1 1 2372 0 1
## 2 1 2130 0 1
## 3 1 2130 0 1
## 4 1 2228 0 1
## 5 1 1773 0 1
## 6 1 1613 0 1
## weight:origin2 weight:origin3 origin
## 1 0 2372 3
## 2 0 2130 3
## 3 0 2130 3
## 4 0 2228 3
## 5 0 1773 3
## 6 0 1613 3So what is the expected miles per gallon for a car with origin == 1 as a function of weight?
\[ \mathtt{mpg} = \beta_0 + \beta_1 \times \mathtt{weight} \]
Now how about a car with origin == 2?
\[ \mathtt{mpg} = \beta_0 + \beta_1 \times \mathtt{weight} + \beta_2 + \beta_4 \times \mathtt{weight} \]
Now think of the graphical representation of these lines. For origin == 1 the intercept of the regression line is \(\beta_0\) and its slope is \(\beta_1\). For origin == 2 the intercept
of the regression line is \(\beta_0 + \beta_2\) and its slope is \(\beta_1+\beta_4\).
ggplot does this when we map a factor variable to a aesthetic, say color, and use the geom_smooth method:

The intercept of the three lines seem to be different, but the slope of origin == 3 looks different (decreases faster) than the slopes of origin == 1 and origin == 2 that look very similar to each other.
Let’s fit the model and see how much statistical confidence we can give to those observations:
auto_fit <- lm(mpg~weight*origin, data=Auto)
auto_fit_stats <- auto_fit %>%
tidy()
auto_fit_stats %>% knitr::kable()| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 43.1484685 | 1.1861118 | 36.3780794 | 0.0000000 |
| weight | -0.0068540 | 0.0003423 | -20.0204971 | 0.0000000 |
| origin2 | 1.1247469 | 2.8780381 | 0.3908033 | 0.6961582 |
| origin3 | 11.1116815 | 3.5743225 | 3.1087518 | 0.0020181 |
| weight:origin2 | 0.0000036 | 0.0011106 | 0.0032191 | 0.9974332 |
| weight:origin3 | -0.0038651 | 0.0015411 | -2.5079723 | 0.0125521 |
So we can say that for origin == 3 the relationship between mpg and weight is different but not for the other two values of origin. Now, there is still an issue here because this could be the result of a poor fit from a linear model, it seems none of these lines do a very good job of modeling the data we have. We can again check this for this model:

The fact that residuals are not centered around zero suggests that a linear fit does not work well in this case.
28.6.1 Additional issues with linear regression
We saw previously some issues with linear regression that we should take into account when using this method for modeling. Multiple linear regression introduces an additional issue that is extremely important to consider when interpreting the results of these analyses: collinearity.
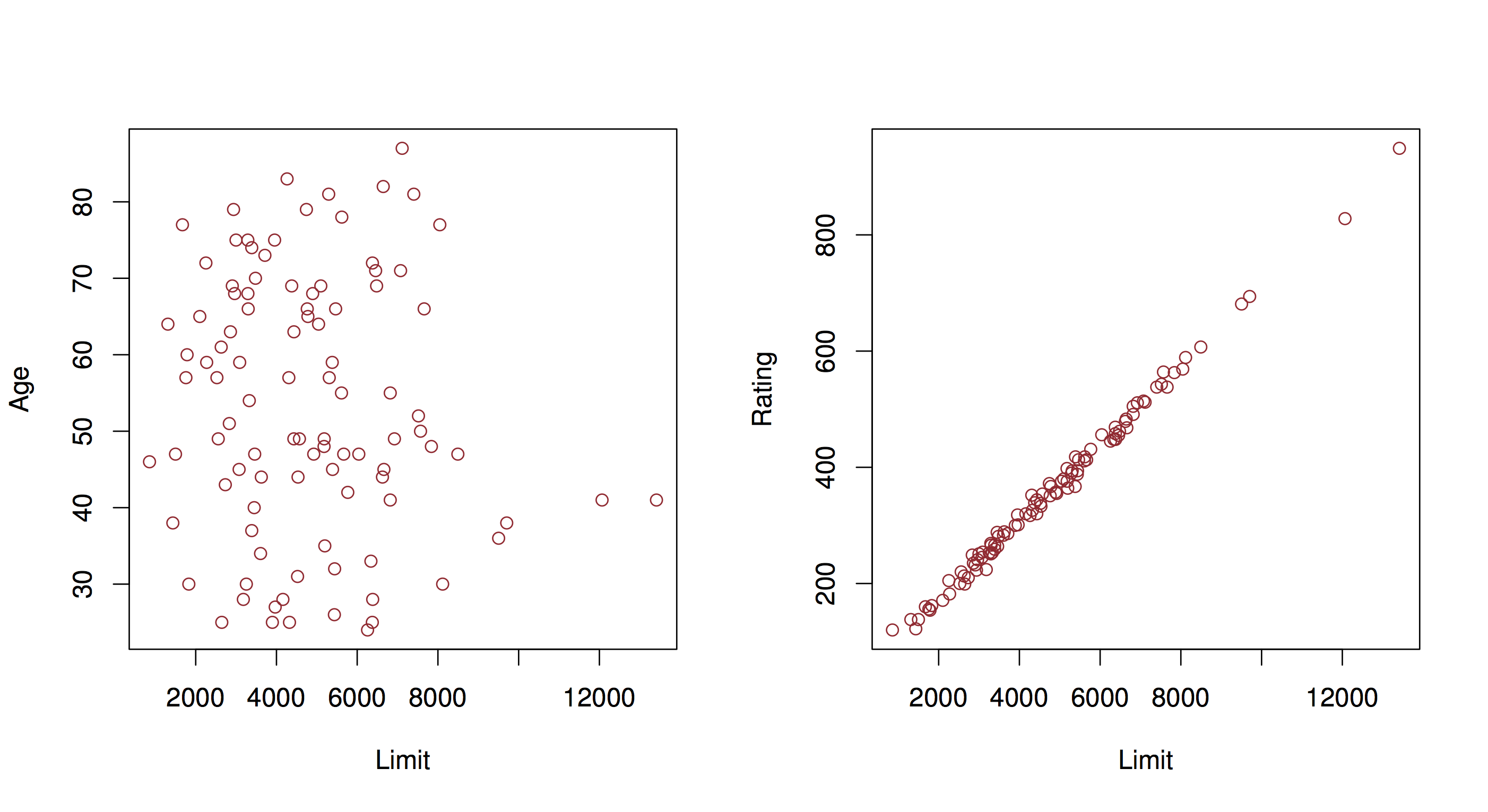
In this example, you have two predictors that are very closely related. In that case, the set of \(\beta\)’s that minimize RSS may not be unique, and therefore our interpretation is invalid. You can identify this potential problem by regressing predictors onto each other. The usual solution is to fit models only including one of the colinear variables.