
Epiviz
Interactive, exploratory visual analysis of genomic data
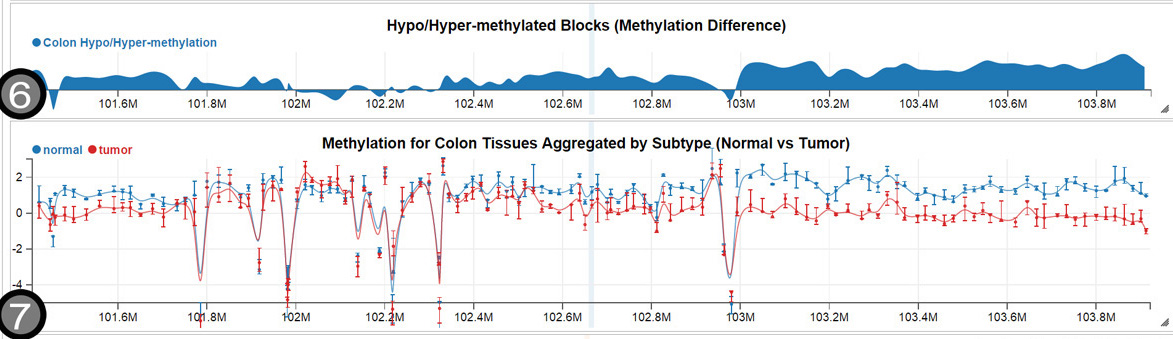 Photo Credit: epiviz
Photo Credit: epiviz
I moved to Genentech Research and Early Development on 6/1/2020. This site is in flux during this transition.
Statistical and computational methods for high-throughput genomics.
Interactive data analysis. Metagenomics. Cancer epigenomics. Transcriptomics.
Our research focuses on efficient and effective interactive analysis of high-throughput genomic data. We develop new methods and tools from multiple areas in the computational and statistical sciences: basic bioinformatics/biostatistics, statistical and machine learning, data visualization and management, and numerical optimization. Applications include cancer epigenetics, metagenomics, pre-processing of measurements from high-throughput assays and disease risk models that integrate high-throughput genomic and other data.
Interactive, exploratory visual analysis of genomic data
Interactive, exploratory visual analysis of metagenomic data
Segment-based RNA-seq analysis
Analysis tools for large high-throughput metagenomics sequencing projects
Methods for analysis of DNA methylation from second-generation sequencing and microarrays.